Did you ever try to build something from sources placed in Eclipse.org? If your .map file contains just a couple of entries - you're OK, but if there are tens of plug-ins to fetch - the mission becomes really impossible, especially during Eclipse.org server maintenance times. I've wrote a simple Ant task, which shortens the build time twice (at least our Hudson shows so). The Ant task is invoked right after the "getMapFiles" PDE builder task, and does very simple steps:
1. Runs "rsync -az" to synchronize local CVS repository with the remote one.
2. Updates .map file to direct fetch process to the local repository.
What you need:
1. Local CVS repository (I used these steps to setup one).
2. Set-up SSH private/public keys to the Eclipse.org, so "rsync" will work seamlessly.
May be this trick is one of CVS advantages over SVN :)
Monday, October 26, 2009
Thursday, October 08, 2009
PDT 2.2.0 early access
Recently, I've posted these instructions for installing PDT 2.2.0 from the update site. The new version of PDT contains numerous performance improvements due to the new indexer. As always, please report bugs if you encounter any.
BTW, big thanks to Jacek Pospychala (and Nickb's support, of course :-]) PDT has moved to using Athena as a builder. Watch live PDT builds if you have permissions, of course :)
BTW, big thanks to Jacek Pospychala (and Nickb's support, of course :-]) PDT has moved to using Athena as a builder. Watch live PDT builds if you have permissions, of course :)
Sunday, July 19, 2009
New DLTK indexing is promising
The last couple of weeks I've been working on improving DLTK indexer, which was derived from JDT as is. The original bug report sounds like: "Indexing must be adapted for dynamic languages". I have to explain this point a little bit. In Java, every element reference is strongly bound to the original declaration. This is why one can calculate this binding during source code parsing and hold it in a memory (probably update it when referenced/referencing elements are changed). This is not the case for dynamic languages, consider this example (PHP):
<?php
function __autoload($class_name) {
require_once $class_name . '.php';
}
$obj = new MyClass();
?>
In this example PHP file is included before the class is loaded, and there's no way for IDE to determine which one. In order to have all JDT-like features in DLTK-based IDE resolution of elements binding is done each time from scratch. This ends up with a lot of queries and updates to index file, which are very I/O intensive operations.
We've tried to implement indexing using H2 database, and the results are really amazing! Here's a screen-cast showing how fast building of full hierarchy for 'Exception' class is using H2 database based index. Comparing to an older implementation I must admit that it's 10 times faster. Due to the fast access to the model most of other features will have great performance as well: Code Assist, Source Navigation, Source Editing, Mark Occurrences, etc...
I hope this will be included into DLTK 2.0.0 and PDT 2.2.0.
<?php
function __autoload($class_name) {
require_once $class_name . '.php';
}
$obj = new MyClass();
?>
In this example PHP file is included before the class is loaded, and there's no way for IDE to determine which one. In order to have all JDT-like features in DLTK-based IDE resolution of elements binding is done each time from scratch. This ends up with a lot of queries and updates to index file, which are very I/O intensive operations.
We've tried to implement indexing using H2 database, and the results are really amazing! Here's a screen-cast showing how fast building of full hierarchy for 'Exception' class is using H2 database based index. Comparing to an older implementation I must admit that it's 10 times faster. Due to the fast access to the model most of other features will have great performance as well: Code Assist, Source Navigation, Source Editing, Mark Occurrences, etc...
I hope this will be included into DLTK 2.0.0 and PDT 2.2.0.
Friday, June 26, 2009
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)

Tuesday, May 19, 2009
@var magic comment
This is a good example how people get used to a bad habits. @var magic comment has appeared first in early Zend Studio, and this is how it was used:

As you can see this magic comment makes content assist know what is the type of $test variable. With PDT 2.0 we have canceled this behaviour due to promising type inference engine, that can resolve variable back to the place where it was declared. For example:

As it turned out later this is not enough for most PHP developers as there are many cases where there's no reference from variable usage to its declaration (if declaration exists at all). One example has changed our mind, and we've decided to fix 260805, 249705 and 257481 ASAP.
One famous MVC framework magically allows to refer to View members from within .phtml script using $this variable. To support this you definitely need something to tell content assist that $this variable is actually an instance of some class even though it appears in a global scope...
Ouch... PHP is full of magic :)
PS: @var comment fixes are available in 2.1.0M7, but I suggest using latest integration build.
Continuous Integration for Eclipse-based product: thoughts
I've been thinking what is the best way to create a fully bottom-up build infrastructure for Eclipse-based product. What I mean by "fully" is:
- Developer commits code.
- A new build starts automatically.
- If the build succeeds - run tests.
- If tests are successful - tag the code.
Advantages of this scheme are the following:
- I'll always know what's the status of the product in CVS.
- I can choose the "best" package and promote it without invoking any builds.
- CVS repository
- Hudson
- Eclipse
As a conclusion: I see a lot of black magic work and hacks to get this done. Or... am I missing some pretty solution here?
Friday, April 10, 2009
"Writing Eclipse plug-ins in PHP"
The GSoC proposal starts gathering scores. Why this idea is so important? PHP developers have a lot of requests for improving the IDE. Why wait for mercy of project committers? Imagine that you can easily use the language (that you're not afraid of) for adding some new functionality to your lovely IDE. Isn't it great? William Candillon, the student that has proposed this project participated already in GSoC in 2006, 2007 and 2008. I'm quite confident that his participation this year will be felicitous for him and for the community too :)
Thursday, March 26, 2009
Good bye, EclipseCon '09!
One more EclipseCon is over. A lot of new thoughts I'm taking away with me. Having a lot of "fun" with PDE builder in the past I was inspired by having a chance to learn about PDE builder wrappers: Dash Athena and Buckminster. Both projects look very interesting, though I haven't tested them yet (Buckminster should be the first one to start with due to .product file support).
I'm still under the impression of Single sourcing RCP and RAP and Runtime Riena and SOA. These give you to understand that Eclipse can be used as a platform for creating simple (or even complex) information systems very quickly. Trying both technologies is "a must", and I gonna do that in a near feature.
There where things that I'm not convinced still in their necessity. For example, who will need a Real Time Shared Editing? Don't tell me about pair programming. I'm in doubt that simultaneous typing can have some benefits. Usually, it's one who's typing and another who's staring at the code behind the shoulder. Another example - Cloud IDE Principle. It would be nice to have something like that (and the reason is NOT, since we don't want to bring source code to the local machine, and then deploy it back), but wait, is Web technology strong enough for that? People are used to rely too much on a single XMLHttpRequest...
Anyway, it's good that world global crisis does not apply on a public interest in Eclipse. It applies on a number of free T-shirts and bags though - I'm coming back without presents...
Sunday, March 08, 2009
PHP 5.3 support in PDT - 2nd stage is over
I think picture is worth a thouthand of words (if this ain't photoshop, of course)
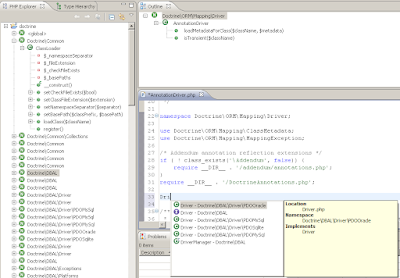
Just a few words more, the following bugs where fixed recently:
261816 - Add namespaces presentation into PHP Explorer.
261817 - Provide Code Assist for PHP 5.3 elements.
261818 - Provide namespace information in the Outline & PHP Explorer views.
264952 - Add USE statement automatically after inserting Code Assist proposal.
Special thanks to the Doctrine Project that provided as with a great PHP application written for PHP 5.3, which we use for testing purposes.
Sunday, January 25, 2009
PHP 5.3 support in PDT: 1st stage is completed
For those of you who are desperately waiting for the PHP 5.3 support in PDT - check out tommorrow's nightly build for the 2.1/HEAD branch. Here's a list of basic features that where defined for the first stage:


PHP 5.3 syntax support: syntax highlighting, no errors in Problem View; sorry for the mess - I tried to put all new language features into one PHP code snippet :-)

Choosing PHP version when creating a new PHP project...
Basic code assit for new keywords...
PHP 5.3 syntax support: syntax highlighting, no errors in Problem View; sorry for the mess - I tried to put all new language features into one PHP code snippet :-)
The next stage will be modeling namespaces... Be prepared, DLTK...
PS: you know the address where you can report bugs, right? :)
Saturday, January 10, 2009
Pedal for Code Assist
Following many complains about unusability of code assist in Eclipse I thought about some interesting construction... Just imaging yourself: your fingers are always free for writing code! No more embarassing CTRL+space shortcuts! Just connect your pedal to the computer, and configure it in the Eclipse preferences:

Do you think this idea can be developed? :)
Tuesday, January 06, 2009
On improving the PHP Inference Engine...
Just committed a new Type Inference "rule" into the PDT 2.1 branch. The following picture illustrates it better :)

Sunday, January 04, 2009
PDT 2.0 Released!
4 days ago PHP Development Tools 2.0 was released, and 20,000 of "early birds" had downloaded and started evaluating its new features. If I'd characterize this release in a few words, I'd concentrate on the following topics:
- PHP Inference Engine: code based Completion and Navigation Engines, Type Hierarchy, Marc Occurrences, Override Indicators, and more...
- Improved Performance and Scallability: faster startup; RAM usage is limited, irregardless how many projects are open.
- Build Path: separate project resources from your source code.
Subscribe to:
Comments (Atom)